Earlier in December, the internet was abuzz with news of Tumblr’s declaration that it would ban adult content on its platform starting December 17. But aside from the legal, social and ethical aspects of the debate, what’s interesting is how the microblogging platform plans to implement the decision.
According to a post by Tumblr support, NSFW content will be flagged using a “mix of machine-learning classification and human moderation.” Which is logical because by some estimates, Tumblr hosts hundreds of thousands of blogs that post adult content and there are millions of individual posts that contain what is deemed adult content. The enormity of the task is simply beyond human labor, especially fora platform that has historically struggledto become profitable.
Deep learning, the subset of artificial intelligence that has become very popular in recent years, is suitable for the automation of cognitive tasks that follow a repetitive pattern such as classifying images or transcribing audio files. Deep learning could help take most of the burden of finding NSFW content off the shoulder of human moderators.
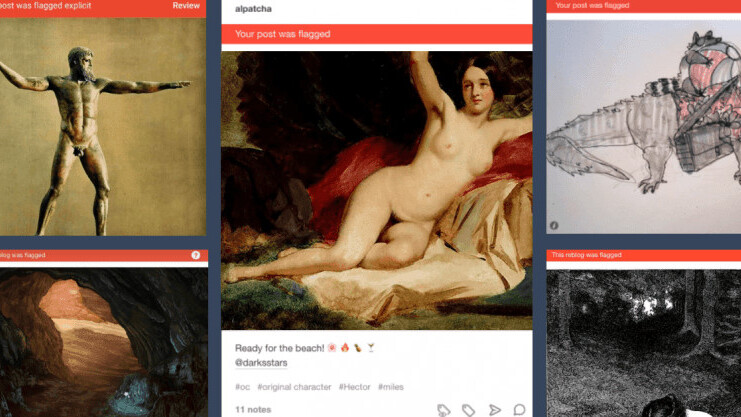
But so far, as Tumblr is testing the waters in flagging content, users have taken to Twitter to show examples of harmless content that Tumblr has flagged as NSFW, which include troll socks, LED jeans and boot-scrubbing design patents.
LED Jeans, too: pic.twitter.com/jtcmYEZGBM
— Sarah Burstein (@design_law) December 4, 2018

The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol' founder Boris, and some questionable AI art. It's free, every week, in your inbox. Sign up now!
Obviously, the folks at Tumblr realize that there are distinct limits to the capabilities of deep learning, which is why they’re keeping humans in the loop. Now, the question is, why does a technology that is as good as—or even better than—humans at recognizing images and objects need the help to make a decision that any human could do without much effort?
A—very brief—primer on deep learning
At the heart of deep learning are neural networks, a software structure roughly designed after the physical structure of the human brain. Neural networks consist of layers upon layers of connected computational nodes (neurons) that run data through mathematical equations and classify them based on their properties. When stacking multiple layers of neurons on each other, deep learning algorithms can perform tasks that were previously impossible to tackle with anything other than the human mind.
Contrary to classical software, which requires human programmers to meticulously program every single behavioral rule, deep learning algorithms develop their own behavior by studying examples. If you provide a neural network with thousands of posts labeled as “adult content” or “safe content,” it will tune the weights of its neurons to be able to classify future content in those two categories. The process is known as “supervised learning” and is currently the most popular way of doing deep learning.
Basically, neural networks classify data based on their similarities with examples they have trained on. So, if a new post bears more visual resemblance with training samples labeled as “adult content,” it will flag it as NSFW.
What it takes to moderate content with deep learning
The problem with content moderation is that it’s more than an image classification problem. Tumblr’s definition of adult content includes “photos, videos, or GIFs that show real-life human genitals or female-presenting nipples, and any content—including photos, videos, GIFs and illustrations—that depicts sex acts.”
This means that the AI that will be flagging adult content will have to solve two different problems. First, it must determine whether a content contains “real-life” imagery and contains “human genitals or female-presenting nipples.” Second, if it’s not real-life content (such as paintings, illustrations and sculptures), it must check to see if it contains depictions of sexual acts.
Theoretically, the first problem can be solved with basic deep learning training. Provide your neural networks with enough pictures of human genitals from different angles, under different lighting conditions, with different backgrounds, etc. and your neural network will be able to flag new images of nudes. In this regard, Tumblr has no shortage of training data, and a team of human trainers will probably be able to train the network in a reasonable amount of time.
But the task becomes problematic when you add exceptions. For instance, users may still be allowed to share non-sexual content such as pictures of breastfeeding, mastectomy, or gender confirmation surgery.
In that case, classification will require more than just comparison of pixels and seeking visual similarities. The algorithm that makes the moderation will have to understand the context of the image. Some will argue that throwing more data will solve the problem. For instance, if you provide the moderation AI with plenty of samples of breastfeeding pictures, it will be able to tell the difference between obscene and breastfeeding content.
Logically, the neural network will decide that breastfeeding pictures include a human infant. But then users will be able to game the system. For instance, someone can edit NSFW images and videos and add the picture of a baby in the corner of the frame to fool the neural network into thinking it’s a breastfeeding image. That is a trick that would never work on a human moderator. But for a deep learning algorithm that simply examines the appearance of images, it can happen very often.
The moderation of illustrations, paintings and sculptures is even harder. As a rule, Tumblr will allow artwork that involves nudity as long as it doesn’t depict a sexual act. But how will it be able to tell the difference between nude art and pornographic content? Again, that would be a task that would be super-easy for a human moderator. But a neural network trained on millions of examples will still make mistakes that a human would obviously avoid.
History shows that in some cases, even humans can’t make the right decision about whether a content is safe or not. A stark example of content moderation gone wrong is Facebook’s Napalm Girl debacle, where the social media removed an iconic Vietnam war photo that featured a naked girl running away from a napalm attack.
Facebook CEO Mark Zuckerberg first defended the decision, stating, “While we recognize that this photo is iconic, it’s difficult to create a distinction between allowing a photograph of a nude child in one instance and not others.” But after a widespread media backlash, Facebook was forced to restore the picture.
What is the extent of deep learning’s abilities in moderating content?
All this said, the cases we mentioned at the beginning of this article are probably going to be solved with more training examples. Tumblr acknowledged that there will be mistakes, and it will figure out how to solve them. With a well-trained neural network, Tumblr will be able to create an efficient system that flags potentially unsafe content with reasonable accuracy and use a medium-sized team of human moderators to filter out the false positives. But humans will stay in the loop.
This thread by Tarleton Gillespie provides a fair account of what probably went wrong and how Tumblr will fix it.
Today, Tumblr is tagging the kinds of ‘adult content’ that will be soon prohibited, after Dec 17. And Tumblr users are posting images that are apparently #TooSexyforTumblr, though clearly not. Patent drawings; raw chicken; vomiting horses; women smoking, puppies, Joe Biden. 1/9
— Tarleton Gillespie (@TarletonG) December 5, 2018
To be clear, adult content is one of the easier categories of content for artificial intelligence algorithms to moderate. Other social networks such as Facebook are doing a fine job of moderating adult content with a mix of AI and humans. Facebook still makes mistakes, such as blocking an ad that contains a 30,000-year-old nude statue, but those are rare enough to be considered edge cases.
The more challenging fields of automated moderation are those where understanding context and meaning play a more important role. For instance, deep learning might be able to flag videos and posts that contain violent or extremist content, but how can it determine whether a flagged post is publicizing violence (prohibited content) or documenting it (allowed content)? Unlike the nudity posts, where there are often distinct visual elements that can tell the difference between allowed and banned content, documentary and publicities can feature the same content while serving totally different goals.
Going deeper into the moderation problem is fake news, where there isn’t even consensus among humans on how to define and moderate it in an unbiased way, let alone automate the moderation with AI algorithms.
Those are the kinds of tasks that will require more human effort. Deep learning will still play an important role in finding potentially questionable content out of the millions of posts that are being published every day, and let humans decide which ones should be blocked. This is the kind of intelligence augmentation that current blends of artificial intelligence are supposed to fulfill, enabling humans to perform at scale.
Until the day (if it ever comes) we create general artificial intelligence, AI that can emulate the cognitive and reasoning process of the human mind, we’ll have plenty of settings where the combination of narrow AI (currently deep learning) and human intelligence will help perform tasks that neither can do on its own. Content moderation is one of them.
This story is republished from TechTalks, the blog that explores how technology is solving problems… and creating new ones. Like them on Facebook here and follow them down here:
Get the TNW newsletter
Get the most important tech news in your inbox each week.