Last week, I wrote an analysis of “Reward Is Enough,” a paper by scientists at DeepMind. As the title suggests, the researchers hypothesize that the right reward is all you need to create the abilities associated with intelligence, such as perception, motor functions, and language.
This is in contrast with AI systems that try to replicate specific functions of natural intelligence such as classifying images, navigating physical environments, or completing sentences.
The researchers go as far as suggesting that with well-defined reward, a complex environment, and the right reinforcement learning algorithm, we will be able to reach artificial general intelligence, the kind of problem-solving and cognitive abilities found in humans and, to a lesser degree, in animals.
The article and the paper triggered a heated debate on social media, with reactions going from full support of the idea to outright rejection. Of course, both sides make valid claims. But the truth lies somewhere in the middle. Natural evolution is proof that the reward hypothesis is scientifically valid. But implementing the pure reward approach to reach human-level intelligence has some very hefty requirements.
In this post, I’ll try to disambiguate in simple terms where the line between theory and practice stands.
Natural selection

In their paper, the DeepMind scientists present the following hypothesis: “Intelligence, and its associated abilities, can be understood as subserving the maximisation of reward by an agent acting in its environment.”
Scientific evidence supports this claim.
Humans and animals owe their intelligence to a very simple law: natural selection. I’m not an expert on the topic, but I suggest reading The Blind Watchmaker by biologist Richard Dawkins, which provides a very accessible account of how evolution has led to all forms of life and intelligence on out planet.
In a nutshell, nature gives preference to lifeforms that are better fit to survive in their environments. Those that can withstand challenges posed by the environment (weather, scarcity of food, etc.) and other lifeforms (predators, viruses, etc.) will survive, reproduce, and pass on their genes to the next generation. Those that don’t get eliminated.
According to Dawkins, “In nature, the usual selecting agent is direct, stark and simple. It is the grim reaper. Of course, the reasons for survival are anything but simple — that is why natural selection can build up animals and plants of such formidable complexity. But there is something very crude and simple about death itself. And nonrandom death is all it takes to select phenotypes, and hence the genes that they contain, in nature.”
But how do different lifeforms emerge? Every newly born organism inherits the genes of its parent(s). But unlike the digital world, copying in organic life is not an exact thing. Therefore, offspring often undergo mutations, small changes to their genes that can have a huge impact across generations. These mutations can have a simple effect, such as a small change in muscle texture or skin color. But they can also become the core for developing new organs (e.g., lungs, kidneys, eyes), or shedding old ones (e.g., tail, gills).
If these mutations help improve the chances of the organism’s survival (e.g., better camouflage or faster speed), they will be preserved and passed on to future generations, where further mutations might reinforce them. For example, the first organism that developed the ability to parse light information had an enormous advantage over all the others that didn’t, even though its ability to see was not comparable to that of animals and humans today. This advantage enabled it to better survive and reproduce. As its descendants reproduced, those whose mutations improved their sight outmatched and outlived their peers. Through thousands (or millions) of generations, these changes resulted in a complex organ such as the eye.
The simple mechanisms of mutation and natural selection has been enough to give rise to all the different lifeforms that we see on Earth, from bacteria to plants, fish, birds, amphibians, and mammals.
The same self-reinforcing mechanism has also created the brain and its associated wonders. In her book Conscience: The Origin of Moral Intuition, scientist Patricia Churchland explores how natural selection led to the development of the cortex, the main part of the brain that gives mammals the ability to learn from their environment. The evolution of the cortex has enabled mammals to develop social behavior and learn to live in herds, prides, troops, and tribes. In humans, the evolution of the cortex has given rise to complex cognitive faculties, the capacity to develop rich languages, and the ability to establish social norms.
Therefore, if you consider survival as the ultimate reward, the main hypothesis that DeepMind’s scientists make is scientifically sound. However, when it comes to implementing this rule, things get very complicated.
Reinforcement learning and artificial general intelligence
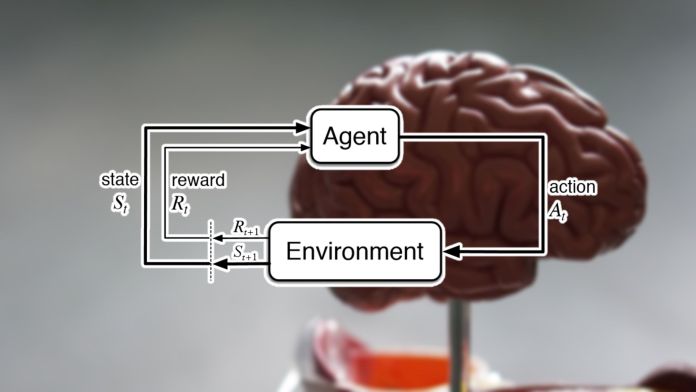
In their paper, DeepMind’s scientists make the claim that the reward hypothesis can be implemented with reinforcement learning algorithms, a branch of AI in which an agent gradually develops its behavior by interacting with its environment. A reinforcement learning agent starts by making random actions. Based on how those actions align with the goals it is trying to achieve, the agent receives rewards. Across many episodes, the agent learns to develop sequences of actions that maximize its reward in its environment.
According to the DeepMind scientists, “A sufficiently powerful and general reinforcement learning agent may ultimately give rise to intelligence and its associated abilities. In other words, if an agent can continually adjust its behavior so as to improve its cumulative reward, then any abilities that are repeatedly demanded by its environment must ultimately be produced in the agent’s behavior.”
In an online debate in December, computer scientist Richard Sutton, one of the paper’s co-authors, said, “Reinforcement learning is the first computational theory of intelligence… In reinforcement learning, the goal is to maximize an arbitrary reward signal.”
DeepMind has a lot of experience to prove this claim. They have already developed reinforcement learning agents that can outmatch humans in Go, chess, Atari, StarCraft, and other games. They have also developed reinforcement learning models to make progress in some of the most complex problems of science.
The scientists further wrote in their paper, “According to our hypothesis, general intelligence can instead be understood as, and implemented by, maximizing a singular reward in a single, complex environment [emphasis mine].”
This is where hypothesis separates from practice. The keyword here is “complex.” The environments that DeepMind (and its quasi-rival OpenAI) have so far explored with reinforcement learning are not nearly as complex as the physical world. And they still required the financial backing and vast computational resources of very wealthy tech companies. In some cases, they still had to dumb down the environments to speed up the training of their reinforcement learning models and cut down the costs. In others, they had to redesign the reward to make sure the RL agents did not get stuck the wrong local optimum.
(It is worth noting that the scientists do acknowledge in their paper that they can’t offer “theoretical guarantee on the sample efficiency of reinforcement learning agents.”)
Now, imagine what it would take to use reinforcement learning to replicate evolution and reach human-level intelligence. First, you would need a simulation of the world. But at what level would you simulate the world? My guess is that anything short of quantum scale would be inaccurate. And we don’t have a fraction of the compute power needed to create quantum-scale simulations of the world.
Let’s say we did have the compute power to create such a simulation. We could start at around 4 billion years ago, when the first life-forms emerged. You would need to have an exact representation of the state of Earth at the time. We would need to know the initial state of the environment at the time. And we still don’t have a definite theory on that.
An alternative would be to create a shortcut and start from, say, 8 million years ago, when our monkey ancestors still lived on earth. This would cut down the time of training, but we would have a much more complex initial state to start from. At that time, there were millions of different lifeforms on Earth, and they were closely interrelated. They evolved together. Taking any of them out of the equation could have a huge impact on the course of the simulation.
Therefore, you basically have two key problems: compute power and initial state. The further you go back in time, the more compute power you’ll need to run the simulation. On the other hand, the further you move forward, the more complex your initial state will be. And evolution has created all sorts of intelligent and non-intelligent life-forms and making sure that we could reproduce the exact steps that led to human intelligence without any guidance and only through reward is a hard bet.
Many will say that you don’t need an exact simulation of the world and you only need to approximate the problem space in which your reinforcement learning agent wants to operate in.
For example, in their paper, the scientists mention the example of a house-cleaning robot: “In order for a kitchen robot to maximize cleanliness, it must presumably have abilities of perception (to differentiate clean and dirty utensils), knowledge (to understand utensils), motor control (to manipulate utensils), memory (to recall locations of utensils), language (to predict future mess from dialogue), and social intelligence (to encourage young children to make less mess). A behavior that maximises cleanliness must therefore yield all these abilities in service of that singular goal.”
This statement is true, but downplays the complexities of the environment. Kitchens were created by humans. For instance, the shape of drawer handles, doorknobs, floors, cupboards, walls, tables, and everything you see in a kitchen has been optimized for the sensorimotor functions of humans. Therefore, a robot that would want to work in such an environment would need to develop sensorimotor skills that are similar to those of humans. You can create shortcuts, such as avoiding the complexities of bipedal walking or hands with fingers and joints. But then, there would be incongruencies between the robot and the humans who will be using the kitchens. Many scenarios that would be easy to handle for a human (walking over an overturned chair) would become prohibitive for the robot.
Also, other skills, such as language, would require even more similar infrastructure between the robot and the humans who would share the environment. Intelligent agents must be able to develop abstract mental models of each other to cooperate or compete in a shared environment. Language omits many important details, such as sensory experience, goals, needs. We fill in the gaps with our intuitive and conscious knowledge of our interlocutor’s mental state. We might make wrong assumptions, but those are the exceptions, not the norm.
And finally, developing a notion of “cleanliness” as a reward is very complicated because it is very tightly linked to human knowledge, life, and goals. For example, removing every piece of food from the kitchen would certainly make it cleaner, but would the humans using the kitchen be happy about it?
A robot that has been optimized for “cleanliness” would have a hard time co-existing and cooperating with living beings that have been optimized for survival.
Here, you can take shortcuts again by creating hierarchical goals, equipping the robot and its reinforcement learning models with prior knowledge, and using human feedback to steer it in the right direction. This would help a lot in making it easier for the robot to understand and interact with humans and human-designed environments. But then you would be cheating on the reward-only approach. And the mere fact that your robot agent starts with predesigned limbs and image-capturing and sound-emitting devices is itself the integration of prior knowledge.
In theory, reward only is enough for any kind of intelligence. But in practice, there’s a trade off between environment complexity, reward design, and agent design.
In the future, we might be able to achieve a level of compute power that will make it possible to reach general intelligence through pure reward and reinforcement learning. But for the time being, what works is hybrid approaches that involve learning and complex engineering of rewards and AI agent architectures.
This article was originally published by Ben Dickson on TechTalks, a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech, and what we need to look out for. You can read the original article here.
Get the TNW newsletter
Get the most important tech news in your inbox each week.