
In a new paper, researchers at OpenAI have revealed details about Codex, a deep learning model that generates software source code. Codex powers Copilot, an “AI pair programmer” tool developed jointly by OpenAI and GitHub. Copilot is currently available in beta test mode to a limited number of users.
The paper is a fascinating read that explains the process through which the scientists at OpenAI managed to repurpose their flagship language model GPT-3 to create Codex. But more importantly, the paper also sheds much-needed light on how far you can trust deep learning in programming.
The “no free lunch” theorem
Codex is a descendent of GPT-3, a massive deep learning language model release last year. The complexity of deep learning models is often measured by the number of parameters they have. In general, a model’s learning capacity increases with the number of parameters. GPT-3 came with 175 billion parameters, more than two orders of magnitude larger than its predecessor, GPT-2 (1.5 billion parameters). GPT-3 was trained on more than 600 gigabytes, more than 50 times larger than GPT-2’s training dataset.
Aside from the huge increase in size, the main innovation of GPT-3 was “few-shot learning,” the capability to perform tasks it wasn’t trained for. The paper that introduced GPT-3 was titled “Language Models are Few-Shot Learners” and stated: “Here we show that scaling up language models greatly improves task-agnostic, few-shot performance [emphasis mine], sometimes even reaching competitiveness with prior state-of-the-art fine-tuning approaches.”
Basically, the premise was a large-enough model trained on a large corpus of text can match or outperform several models that are specialized for specific tasks.
But according to the new paper by OpenAI, none of the various versions of GPT-3 were able to solve any of the coding problems used to evaluate Codex. To be fair, there were no coding samples in GPT-3’s training dataset, so we can’t expect it to be able to code. But the OpenAI scientists also tested GPT-J, a 6 billion-parameter model trained on The Pile, an 800-gigabyte dataset that includes 95 gigabytes of GitHub and 32 gigabytes of StackExchange data. Opesolved 11.4 percent of the coding problems. Codex, a version of GPT-3’s 12-billion parameter fine-tuned on 159 gigabytes of code examples from GitHub, solved 28.8 percent of the problems. A separate version of Codex, called Codex-S, which was fine-tuned through supervised learning boosted the performance to 37.7 percent (other GPT and Codex models are trained through unsupervised learning).
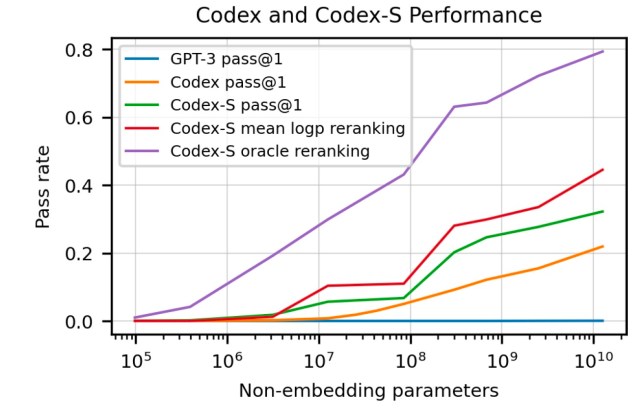
Codex proves that machine learning is still ruled by the “no free lunch” theorem (NFL), which means that generalization comes at the cost of performance. In other words, machine learning models are more accurate when they are designed to solve one specific problem. On the other hand, when their problem domain is broadened, their performance decreases.
Codex can perform one specialized task (transforming function descriptions and signatures into source code) with high accuracy at the cost of poor natural language processing capabilities. On the other hand, GPT-3 is a general language model that can generate decent text about a lot of topics (including complicated programming concepts) but can’t write a single line of code.
Size vs cost

The experiments of OpenAI’s researchers show that the performance of Codex improved as they increased the size of the machine learning model. At 300 million parameters, Codex solved 13.2 percent of the evaluation problems against the 28.8 percent performance of the 12-billion-parameter model.
But the full version of GPT-3 is 175 billion parameters, a full order of magnitude larger than the one used to create Codex. Wouldn’t training the larger model on the Codex training data yield better results?
One probable reason for stopping at 12 billion could be the dataset size. A larger Codex model would need a larger dataset. Training it on the 159-gigabyte corpus would probably cause overfitting, where the model becomes very good at memorizing and rehearsing its training examples and very bad at dealing with novel situations. Gathering and maintaining larger datasets is an expensive and time-consuming process.
An equally vexing problem would be the cost of Codex. Aside from a scientific experiment, Codex was supposed to become the backbone of a future product that can turn in profits for a research lab that is quasi-owned by a commercial entity. As I’ve already discussed before, the costs of training and running the 175-billion GPT-3 model would make it very hard to develop a profitable business model around it.
However, a smaller but fine-tuned version of GPT-3 would be much more manageable in terms of profits and losses.
Finally, as OpenAI’s experiments show, Codex’s size/performance ratio follows a logarithmic scale. This means that performance gains gradually reduce as you increase the size of the model. Therefore, the added costs of gathering data and training and running the larger model might not be worth the small performance boost.
And note that code generation is a very lucrative market. Given the high hourly salaries of programmers, even saving a few hours’ worth of coding time per month would be enough to cover the subscription fees of Codex. In other domains where labor is less expensive, automating tasks with large language models will be more challenging from a profit and loss perspective.
Generating vs understanding code
One thing that needs to be reminded is that, no matter how fascinating Codex’s output is, the deep learning model does not understand programming. Like all other deep learning–based language models, Codex is capturing statistical correlations between code fragments.
In their paper, the OpenAI scientists acknowledge that Codex “is not sample efficient to train” and that “even seasoned developers do not encounter anywhere near this amount of code over their careers.”
They further add that “a strong student who completes an introductory computer science course is expected to be able to solve a larger fraction of problems than Codex-12B.”
Here’s an interesting excerpt from the paper: “We sample tokens from Codex until we encounter one of the following stop sequences: ‘\nclass’, ‘\ndef’, ‘\n#’, ‘\nif’, or ‘\nprint’, since the model will continue generating additional functions or statements otherwise.”
This means that Codex will mindlessly continue to generate code even if it has already finished the block that addresses the problem stated in the prompt.
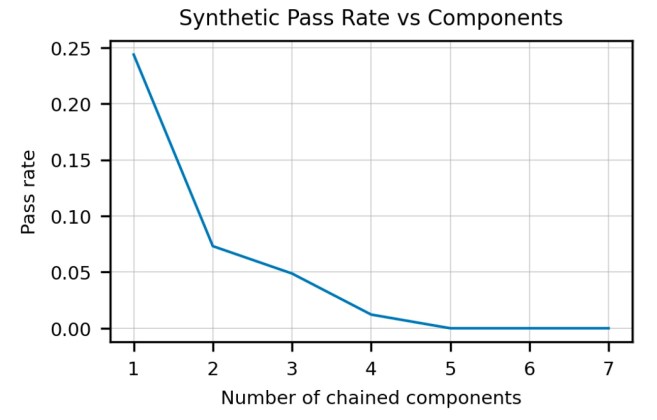
This is a scheme that works well when you want to solve simple problems that recur time and again. But when you zoom out and try to write a large program that tackles a problem that must be solved in multiple steps, the limits of Codex become evident.
OpenAI’s scientists found that as the number of components in the function description increased, the model’s performance decreased exponentially.
“This behavior is uncharacteristic of a human programmer, who should be able to correctly implement a program for a chain of arbitrary length if they can do so for a chain of length two,” the researchers write in their paper.
Further exposing Codex’s lack of understanding of program structure and code is the fact that it “can recommend syntactically incorrect or undefined code, and can invoke functions, variables, and attributes that are undefined or outside the scope of the codebase,” according to the paper. Practically, this means that in some cases, the machine learning model will stitch together different pieces of code it has previously seen, even if they don’t fit together.
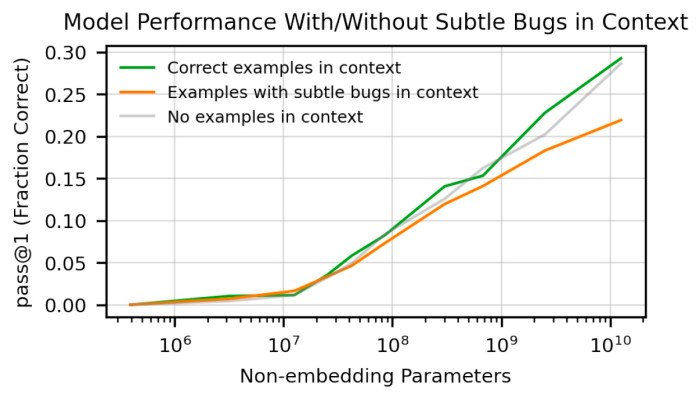
In their paper, the researchers also discuss “misalignment” issues in Codex, where the model can solve a specific problem but doesn’t do so due to various mistakes. Codex uses the contents of the file you’re working on as context to generate its output. If your code contains subtle bugs (which is quite normal if you’re a human programmer), Codex may “deliberately” suggest code that superficially appears good but is incorrect, the researchers warn.
Misalignment is an interesting phenomenon that needs further study. But OpenAI’s experiments further show that “misalignment would likely persist and even get worse if data, parameters, and training time were scaled up,” which might be another reason for keeping the model’s size balanced at 12 billion parameters.
The paper also talks extensively about the possibility for Codex to produce deprecated and vulnerable code (which is worthy of a separate article, so I didn’t discuss it here).
Responsible use and reporting of AI
As I said after the release of Copilot, “AI Pair Programmer,” the term used on GitHub’s webpage for Copilot, is inaccurate.
Codex is not a programmer. And it’s also not going to take your job (if you’re a programmer). Coding is just part of what programmers do. OpenAI’s scientists observe that in its current state Codex “may somewhat reduce the cost of producing software by increasing programmer productivity,” but it won’t replace the other tasks that software developers regularly do, such as “conferring with colleagues, writing design specifications, and upgrading existing software stacks.”
Mistaking Codex for a programmer can also lead to “over-reliance,” where a programmer blindly approves any code generated by the model without revising it. Given the obvious and subtle mistakes Codex can make, overlooking this threat can entail quality and security risks. “Human oversight and vigilance is required for safe use of code generation systems like Codex,” OpenAI’s researchers warn in their paper.
Overall, the reaction of the programmer community shows that Codex is a very useful tool with a possibly huge impact on the future of the software industry. At the same time, given the hype surrounding the release of Copilot, it is important to understand its unwanted implications. In this regard, it is worth commending the folks at OpenAI for responsibly studying, documenting, and reporting the limits and threats of Codex.
This article was originally published by Ben Dickson on TechTalks, a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech, and what we need to look out for. You can read the original article here.
Get the TNW newsletter
Get the most important tech news in your inbox each week.